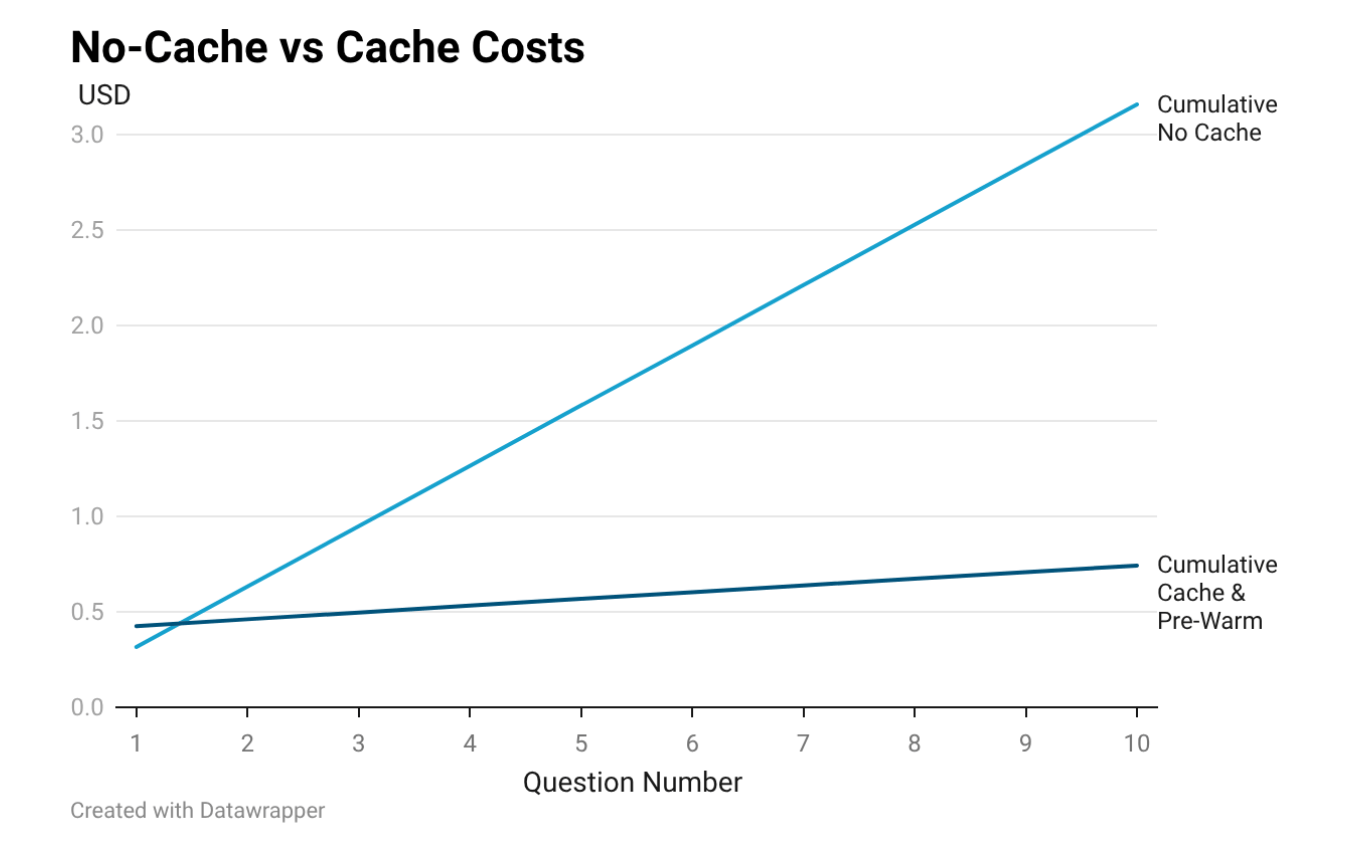1. Goal
The first layer of customer support for most applications is now an AI assistant. That AI assistant typically needs a few messages of conversation before it has enough context to be useful. In most shopping or banking UX, a help button is available right from an order or disclosure page. Through prompt caching, you can pre-warm the assistant with information the user is already looking at, skipping unnecessary back and forth. This tutorial walks through an implementation of this flow and points out when prompt caching is worth it. Anthropic’s broader cookbook on prompt caching is a better way to get familiar with the technique’s other applications. The cookbook’s examples cache more conservatively than this tutorial’s eager-on-click approach: Anthropic’s Prompt Caching Cookbook2. TLDR
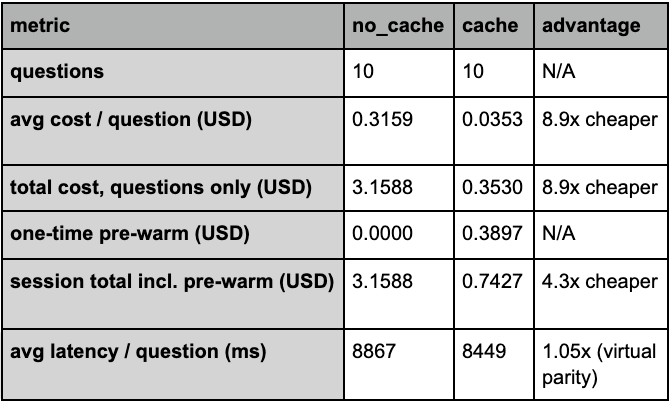
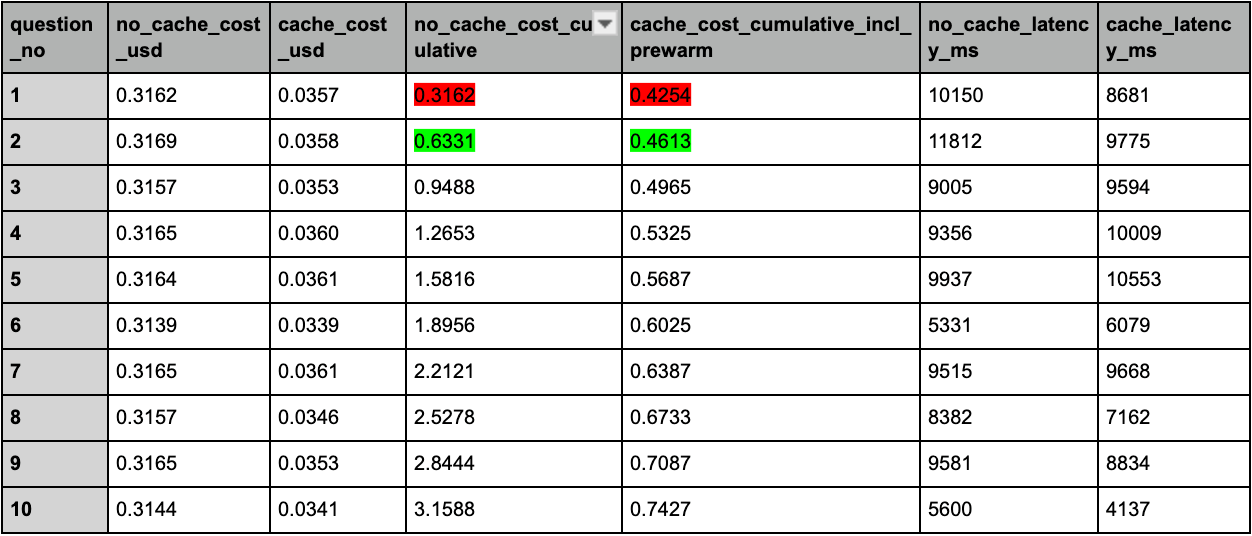
After a user asks your bot 2 questions about the same document, prompt caching becomes cheaper than no-caching. By question 10, caching is 4x cheaper. Consider using prompt caching if users are asking more than one question about a document. This eager-on-intent flow prompt caches the document as soon as a user clicks on the help button, but it doesn’t meaningfully reduce latency in this demo. Frankenstein has around 100K tokens. Anthropic’s cookbook run with Pride and Prejudice at roughly 190K tokens saw a 3.3x speedup. The latency benefit prompt caching can offer comes from a reduction in prefix reprocessing. Frankenstein doesn’t reach this threshold. Pride and Prejudice does. This comparison cost 3.56 USD. 2.84 USD for no-cache and 0.71 USD for cache.3. Prerequisites
This tutorial uses Anthropic’s javascript SDK, Python3, NODE and HTML. Anthropic JS SDK You will also need an API key. You can generate one by clicking “Generate API Key” on your home dashboard after logging in Anthropic Dev Dash. In your editor of choice (I use VS Code), I recommend creating a .env file and pasting this API key in it. Anthropic will not provide your API key again once it’s generated. If you decide to use version control like git & github, make sure to save it into a folder that isn’t updated like .gitignore. Otherwise, you’ll be broadcasting free tokens to the world wide web. Last, we’re using Mary Shelley’s Frankenstein as our reference document. Gutenberg Project Frankenstein4. Important Definitions
Prefix: A prefix is a contiguous string of information. It begins at the start of a request and ends at a predetermined cut off called a cache breakpoint. Prefixes are stored in the cache and matched by exact token sequence. Cache Breakpoint: The point where a prefix ends. It is determined by the cache_control field. The breakpoint and everything prior is included in the prefix. Block: A block is the smallest addressable unit in the API. Each block has a type, text, image, document, tool_use, tool_result and corresponding data. The message’s content field is an array of blocks. A single message can contain many. The cache_control field attaches to a block, not a message or request. Blocks can have very different token sizes. A single text block could have 5 or 50k tokens. Use the usage field in API responses to see token counts. Cache Hit: A match between prefixes. The cached prefix and the prefix of a new request match so the input can be reused at roughly 10% the standard input token rate. A new response is still generated. Cache Miss: A new request’s prefix doesn’t match a cached entry. The API processes the prompt and writes it to a prefix in the cache for next time if cache_control is set. This cache write costs roughly 25% more than standard input tokens. If cache_control isn’t set, the request is processed at the standard input token rate, but no cache is set.5. The Pattern
In this tutorial, we’ll be implementing prompt caching on an AI assistant that is triggered by a user’s click of a help button. We eliminate a common UX back and forth where the assistant asks “what can I help with?”, by populating Claude’s context before the user’s first question. This is an eager-on-intent approach. You can pre-warm at any stage however. These will have different cost implications. You could pre-warm as soon as the page loads (eager-on-load, always incur 1.25x cache cost) or wait for the user to ask your chat assistant a relevant question (lazy-load, only incur cache cost when user confirms it’s relevant). How you decide to pre-warm should be highly dependent on how people use your site. Eager-on load will fire every page view, even bounces. Lazy will take more time to get to your user’s first question. This tutorial uses eager-in-intent because we assume a user who clicks on a help button is a high-confidence intent signal.6. Tutorial Snippets
6.1 Two HTML Buttons
6.2 Cache Warm Up
Server — “Warm up” is a throwaway call whose only job is to write the prefix into cache:6.3 The Ask Function
server server.js:63,162 + client index.html:4236.4 The Simulation Questions
The 10 simulation questions — simulate.py (new, runnable)7. Cost analysis
A prompt cache costs 1.25x more than a single question, so this pre-warm call costs more than the first question without a cache. By question 2 of this demo, the per-question savings have overcome that upfront cost. By question 10, the cached path is 4.3x cheaper overall.